Appearance
前言
栈 在日常生活中的应用非常广泛,比如我们最熟悉不过的十进制转二进制、迷宫求解等等问题。同时,它在前端中的应用也非常广泛,很多小伙伴都会误以为 栈 在前端中的应用很少,但殊不知的是,我们写的每一个程序,基本上都会用到 栈 这个数据结构。比如,函数调用堆栈、数据的深拷贝和浅拷贝……。
所以呢,对于一个前端工程师来说, 栈 结构是一个必学的知识点。在接下来的这篇文章中,将讲解关于 栈 在前端中的应用。
一、栈是什么
- 栈是一种只能在表的一端(栈顶)进行插入和删除运算的线性表;
- 只能在栈顶运算,且访问结点时依照后进先出 (LIFO) 或先进后出 (FILO) 的原则。
二、栈的应用场景
- 需要后进先出的场景;
- 比如:十进制转二进制、迷宫求解、马踏棋盘、判断字符串是否有效、函数调用堆栈……。
三、前端与栈:深拷贝与浅拷贝
1、JS 数据类型
谈到堆栈,我们需要先来了解一下关于 js 的两种数据类型。
(1)js 数据类型的分类
首先,JavaScript 中的数据类型分为基本数据类型和引用数据类型。
了解完分类以后,相信很多小伙伴心里有一个疑惑:这两个数据类型是什么呢?且在内存中是存放在哪里呢?
(2)js 数据类型的定义和存储方式
基本数据类型:
基本数据类型,是指 Numer 、 Boolean 、 String 、 null 、 undefined 、 Symbol(ES6新增的) 、 BigInt(ES2020) 等值,它们在内存中都是存储在 栈 中的,即直接访问该变量就可以得到存储在 栈 中的对应该变量的值。
若将一个变量的值赋值给另一个变量,则这两个变量在内存中是独立的,修改其中任意一个变量的值,不会影响另一个变量。这就是基本数据类型。
引用数据类型:
那引用数据类型呢,是指 Object 、 Array 、 Function 等值,他们在内存中是存在于 栈和堆 当中的,即我们要访问到引用类型的值时,需要先访问到该变量在 栈 中的地址(这个地址指向堆中的值),然后再通过这个地址,访问到存放在 堆 中的数据。这就是引用数据类型。
这样说可能有点抽象,让我们用一张图来理解一下。
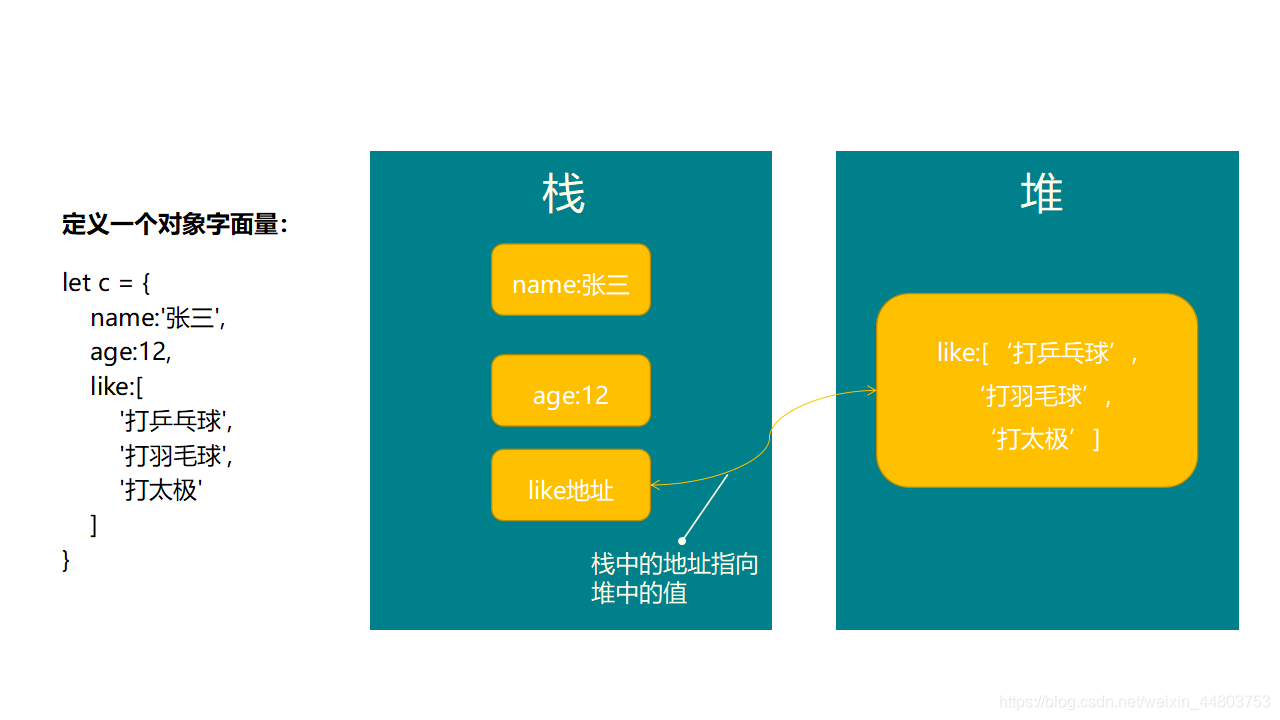
从上图中可以看到, name 和 age 的值都是基本数据类型,所以他们指向程序中 栈 的位置。而 like 是数组类型,也就是引用数据类型,所以在 栈 中,它先存放了一个 like 的地址,之后再把 like 对应的值,存放到 堆 当中。
了解完数据类型和其存储方式后,在面试中,还有可能被问到如何判断某一个数据的类型是什么?什么意思呢?比如说,给你一个数字 7 ,需要你来判断它是什么,我们都知道它是 Number 类型,但很多时候止步于如何做才能判断它是一个 Number 类型。接下来将详细介绍三种判断数据类型的方法。
(3)js 数据类型的判断方式
常用判断方式:typeof、instanceof、===
1)typeof:
定义:返回数据类型的字符串表达(小写)
用法:typeof + 变量
可以判断:
undefined/ 数值 / 字符串 / 布尔值 /function( 返回undefined/number/string/boolean/function)null、object与array(null、array、object 都会返回object)
以下给出代码演示:
js
<script type="text/javascript">
console.log(typeof "Tony"); // 返回 string
console.log(typeof 5.01); // 返回 number
console.log(typeof false); // 返回 boolean
console.log(typeof undefined); // 返回 undefined
console.log(typeof null); // 返回 object
console.log(typeof [1,2,3,4]); // 返回 object
console.log(typeof {name:'John', age:34}); // 返回 object
</script>2)instanceof:
定义:判断对象的具体类型
用法:b instanceof A → b 是否是 A 的实例对象
可以判断:
专门用来判断对象数据的类型:
Object,Array与Function判断
String,Number,Boolean这三种类型的数据时,直接赋值为false,调用构造函数创建的数据为true
以下给出代码演示:
js
<script type='text/javascript'>
let str = new String("hello world") //console.log(str instanceof String); →
true str = "hello world" //console.log(str instanceof String); → false let num
= new Number(44) //console.log(num instanceof Number); → true num = 44
//console.log(num instanceof Number); → false let bool = new Boolean(true)
//console.log(bool instanceof Boolean); → true bool = true //console.log(bool
instanceof Boolean); → false
</script>js
<script type="text/javascript">
let items = [];
let object = {};
function reflect(value) {
return value;
}
console.log(items instanceof Array); // true
console.log(items instanceof Object); // true
console.log(object instanceof Object); // true
console.log(object instanceof Array); // false
console.log(reflect instanceof Function); // true
console.log(reflect instanceof Object); // true
</script>3)===:
可以判断:undefined,null
以下给出代码演示:
js
<script type='text/javascript'>
let str; console.log(typeof str, str === undefined); //'undefined', true let
str2 = null; console.log(typeof str2, str2 === null); // 'object', true
</script>讲到这里,我们了解了 js 的两种数据类型,以及两种数据类型相关的存储方式和判断方式。那么,接下来将讲解他们在前端中常见的应用,深拷贝和浅拷贝。
2、深究浅拷贝和深拷贝
(1)浅拷贝
1)定义
所谓浅拷贝,就是一个变量赋值给另一个变量,其中一个变量的值改变,则两个变量的值都变了,即对于浅拷贝来说,是数据在拷贝后,新拷贝的对象内部 仍然有一部分数据 会随着源对象的变化而变化。
2)代码演示
js
// 浅拷贝-分析
function shallowCopy(obj) {
let copyObj = {};
for (let i in obj) {
copyObj[i] = obj[i];
}
return copyObj;
}
// 浅拷贝-实例
let a = {
name: '张三',
age: 19,
like: ['打篮球', '唱歌', '跳舞'],
};
//将a拷贝给b
let b = shallowCopy(a);
a.name = '李四';
a.like[0] = '打乒乓球';
console.log(a);
/*
*{
name: '李四',
age: 19,
like: ['打乒乓球', '唱歌', '跳舞']
}
*/
console.log(b);
/*
*{
name: '张三',
age: 19,
like: ['打乒乓球', '唱歌', '跳舞']
}
*/3)图例
从上面中的代码可以看到,我们明明把 a 对象拷贝给 b 了,但是 b 最终打印出来的结果部分数据不变,部分数据却变了。这个时候很多小伙伴就很疑惑了,这究竟是为什么呢?
我们回顾上面所说到的关于 引用数据类型 的知识点,上述代码中的 b 中的 like ,是一个数组,也就是引用数据类型。我们都知道,引用数据类型的数据是存放于 栈和堆 当中的,所以上述中的 like 数组,我们将它视为一个地址,这个地址存放于 栈 当中,同时,这个地址里面的数据,就指向于 堆 当中。我们来看一下图例。
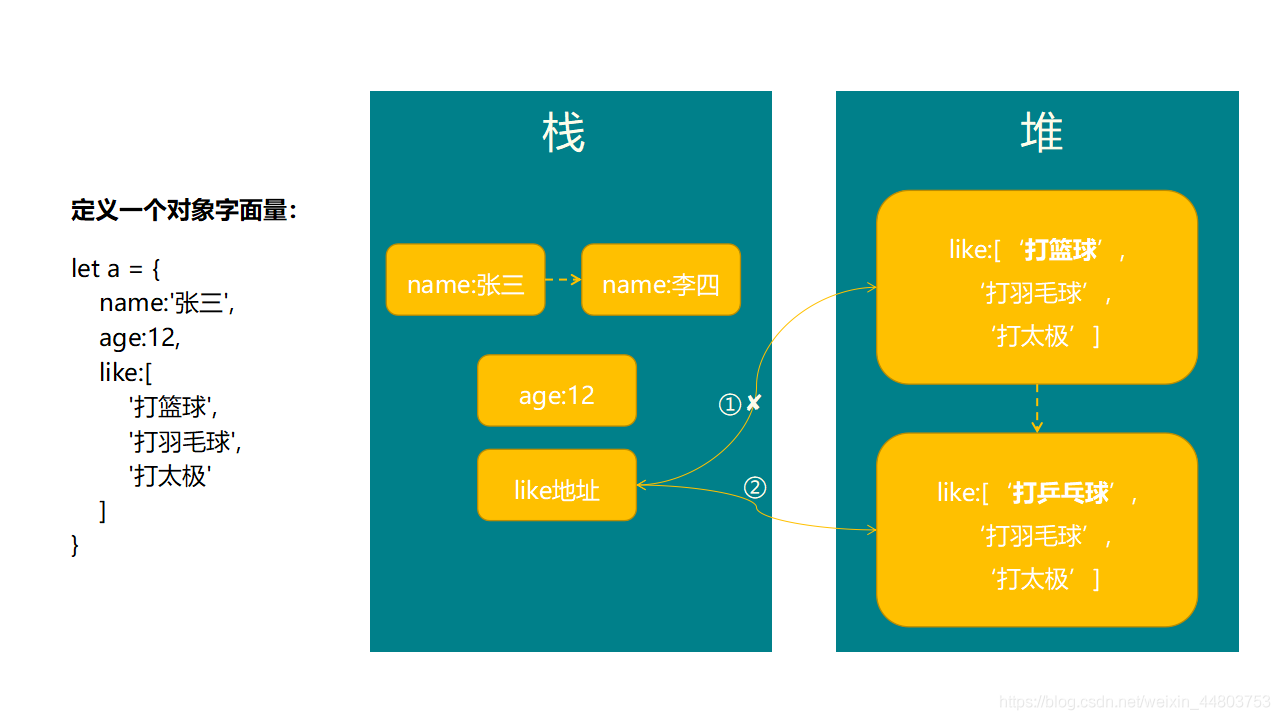
从上图中可以看到,当对 a 中 like 的数据进行改变时,它对应的数据在 堆 中改变。而 b 拷贝后的 like 地址所指向的数据,也是跟 a 一样在 堆 中的位置。也就是说,a 和 b 中的 like 地址,它们的数据指向 堆 中的同一个位置,所以 b 在拷贝完数据以后,部分数据会随着 a 的变化而变化。这就是浅拷贝。
讲完浅拷贝,接下来来了解深拷贝。
(2)深拷贝
1)定义:深拷贝就是,新拷贝的对象内部所有数据都是 独立存在 的,不会随着源对象的改变而改变。
2)深拷贝有两种方式:递归拷贝和利用 JSON 函数进行深拷贝。
- 递归拷贝的实现原理是:对变量中的每个元素进行获取,若遇到基本类型值,直接获取;若遇到引用类型值,则继续对该值内部的每个元素进行获取。
- JSON 深拷贝的实现原理是:将变量的值转为字符串形式,然后再转化为对象赋值给新的变量。
3)局限性:深拷贝的局限性在于,会忽略 undefined,不能序列化函数,不能解决循环引用的对象。
4)代码演示
js
// 深拷贝-递归函数方法分析
function deepCopy(obj) {
// 判断是否为引用数据类型
if (typeof obj === 'object') {
let result = obj.constructor === Array ? [] : {};
for (let i in obj) {
result[i] = typeof obj[i] === 'object' ? deepCopy(obj[i]) : obj[i];
}
return result;
}
// 为基本数据类型,直接赋值返回
else {
return obj;
}
}
// 深拷贝-递归函数方法实例
let c = {
name: '张三',
age: 12,
like: ['打篮球', '打羽毛球', '打太极'],
};
let d = deepCopy(c);
c.name = '李四';
c.like[0] = '打乒乓球';
console.log(c);
/*
*{
name: '李四',
age: 19,
like: ['打乒乓球', '打羽毛球', '打太极']
}
*/
console.log(d);
/*
*{
name: '张三',
age: 19,
like: ['打篮球', '打羽毛球', '打太极']
}
*/js
// 深拷贝-JSON函数方法实例
let c = {
name: '张三',
age: 19,
like: ['打篮球', '唱歌', '跳舞'],
};
let d = JSON.parse(JSON.stringify(c));
// 注意: JSON函数做深度拷贝时不能拷贝正则表达式,Date,方法函数等
c.name = '李四';
c.like[0] = '打乒乓球';
console.log(c);
/*
*{
name: '李四',
age: 19,
like: ['打乒乓球', '唱歌', '跳舞']
}
*/
console.log(d);
/*
*{
name: '张三',
age: 19,
like: ['打篮球', '唱歌', '跳舞']
}
*/从上述代码中可以看到,深拷贝后的数据各自都是独立存在的,不会随着源对象的变化而变化,这就是深拷贝。不过值得注意的是,在我们平常的开发中,用的更多的是递归函数来进行深拷贝,原因在于递归函数方法的灵活性会更强一点。而 JSON 函数方法有很多局限性,在做深度拷贝时不能拷贝正则表达式、Date、方法函数等。
四、前端与栈:函数调用堆栈
在我们平常的开发中,经常会写很多函数,那函数在执行过程中,其实就是一个调用堆栈。接下来我们用一段代码来演示。
js
const func1 = () => {
func2();
console.log(3);
};
const func2 = () => {
func3();
console.log(4);
};
const func3 = () => {
console.log(5);
};
func1(); //5 4 3看到这里,很多小伙伴心中可能已经在构思整段代码的执行顺序是什么样的。接下来用一张图来展示。
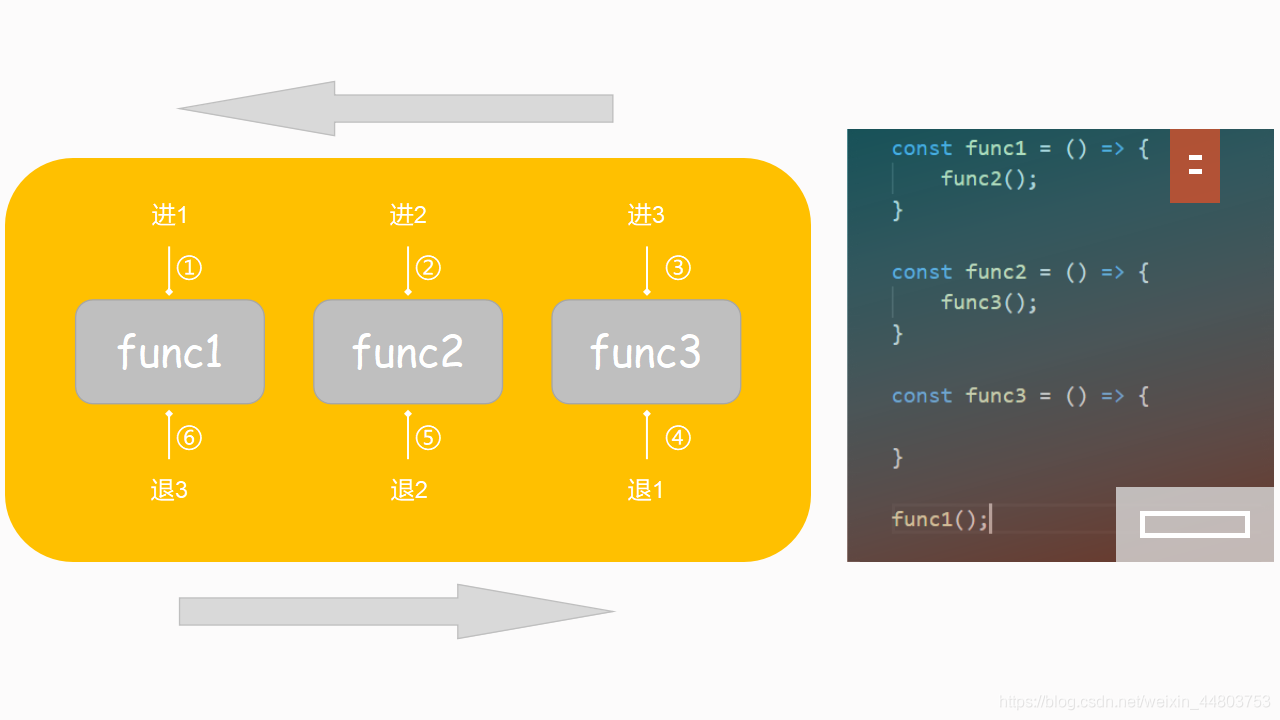
我们都知道, JavaScript 的执行环境是单线程的。所谓单线程是指一次只能完成一个任务,如果有多个任务,就必须排队,只有当前面一个任务完成时,才能执行后面一个任务,以此类推。上图中所演示的,即每调用一个函数,如果里面还有新的函数,那么就先把它放到调用堆栈里,等到所有任务都放满以后,开始依次执行。
而函数调用堆栈是一个典型的栈的数据结构,遵循后进先出原则,当 func1 , func2 , func3 依次放进调用栈后, 遵循后进先出原则 ,那么 func3 函数的内容会先被执行,之后是 func2 ,最后是 func1 。这就是函数调用堆栈。